
ใช้ GPU ในงาน AI แบบคุ้มค่าสุดๆ ด้วย NVIDIA Run:ai บน VMware Cloud Foundation

vmware-administrator
5 Mar 2026 AT 23:03 GMT+0700

ทรัพยากรประมวลผลสำหรับงาน AI ดูจะแพงขึ้นทุกวัน และในบางช่วงการคลาดแคลนชิปและหน่วยความจำ ยิ่งส่งผลทำให้มีการปรับราคา GPU สูงขึ้นมาก ทั้งนี้งาน AI อาจไม่จำกัดอยู่แค่ On-premise หรือ Private Cloud แต่หลายองค์กรอาจบาลานซ์ความคุ้มค่าของบริการคลาวด์เข้ามาด้วย แต่ปัญหาคือที่ผ่านมาผู้ใช้งานส่วนใหญ่ยังไม่สามารถบริหารจัดการทรัพยากรได้อย่างสูงสุดสำหรับ AI นั่นคือที่มาของ NVIDIA Run:ai ซึ่งความคุ้มค่านี้จะยิ่งทวีคูณและปลอดภัยยิ่งขึ้นเมื่อจับคู่เข้ากับ VMware Cloud Foundation
รู้จักกับ NVIDIA Run:ai แพลตฟอร์มบริหารจัดการทรัพยากรด้าน AI
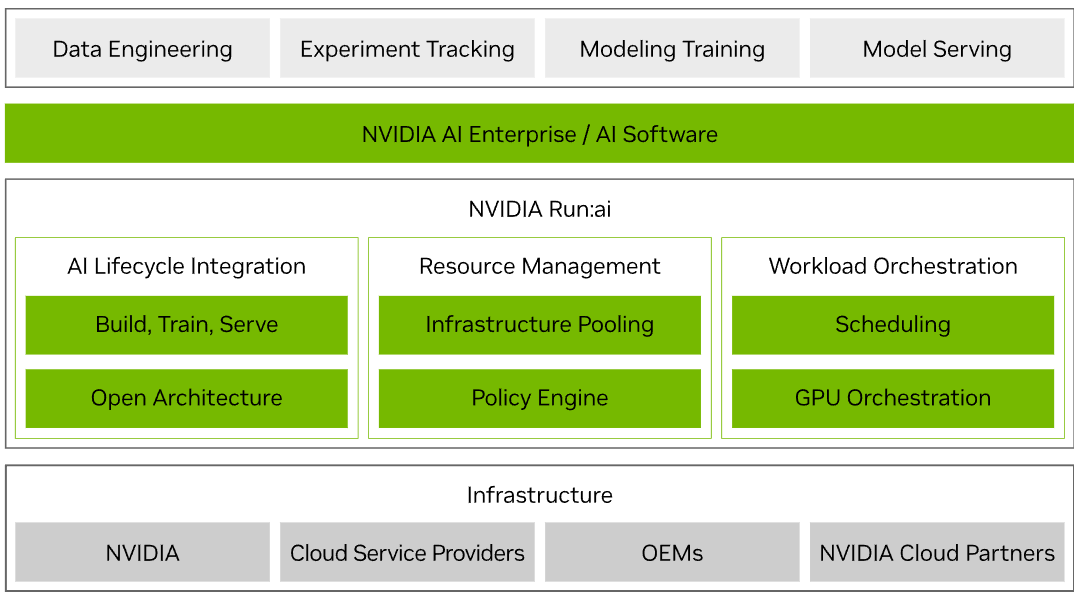
NVIDIA Run:ai เป็นแพลตฟอร์มที่ช่วยในการรวบรวมทรัพยากร GPU จากที่ต่างๆเข้ามาเป็นส่วนกลาง(Pooling)สำหรับงาน AI ไม่ว่าจะเป็น Public Cloud, Private Cloud, On-premise และ Hybrid Cloud โดยพระเอกของงานคือความสามารถที่เรียกว่า ‘Dynamic Resource Allocation’ ที่ทำให้สามารถจองทรัพยากรได้ตามความต้องการและไม่ปล่อยทรัพยากรไว้โดยเปล่าประโยชน์(Idle)
ไม่เพียงเท่านั้น NVIDIA Run:ai ยังชูโรงด้วยความสามารถการเชื่อมต่อที่ง่ายดายผ่าน API รองรับ AI Framework และเครื่องมือด้าน Machine Learning หรือโซลูชัน Third-party อย่างกว้างขวาง ซึ่งทาง NVIDIA ได้กล่าวถึงศักยภาพของแพลตฟอร์มที่ช่วยงาน AI อย่างครบวงจร ตั้งแต่การพัฒนางาน AI, Training และ Deploy Workload ไปยังปลายทางต่างๆ
การรวมศูนย์ทรัพยากรเช่นนี้ประกอบกับความสามารถในด้าน Policy ยังช่วยให้องค์กร กำหนดเป้าหมายการทำงานได้คุ้มค่าตาม ROI ขยายทรัพยากรได้เท่าทันต่อความต้องการในการใช้งาน และที่สำคัญที่สุดคือการทำงานผ่าน NVIDIA Run:ai เสมือนเป็นตัวกลางที่คอยควบคุมสภาพแวดล้อมจากหลายๆที่ ซึ่งเมื่อมีการเปลี่ยนแปลงทรัพยากรผู้ใช้งานก็ไม่จำเป็นต้องเข้าไปแก้ไขโค้ดสำหรับปลายทางนั้นๆ
NVIDIA Run:ai มีทางเลือกในการใช้งานได้ 2 รูปแบบ คือ
- SaaS – ส่วน Control Plane จะอยู่ใน Cloud ซึ่งจะต้องมีการเปิดทางการสื่อสารระหว่าง AI Workload ให้วิ่งออกไปถึง Control Plane
- Self-Hosted – ส่วน Control Plane จะอยู่บน On-premise ในรูปแบบนี้จะทำให้องค์กรมีอำนาจในการควบคุมได้มากกว่า ซึ่งจะเป็นรูปแบบของการติดตั้งบน VCF ที่เราจะกล่าวถึงต่อไป
คุ้มค่าต่อที่สองด้วย VMware Cloud Foundation
NVIDIA Run:ai เป็นแพลตฟอร์มที่สั่งงานควบคุมการใช้ GPU ให้เกิดความคุ้มค่าสูงสุด ช่วยให้การจัดการ Lifecycle ของ GPU เป็นไปได้ง่าย ด้วยการรวมทรัพยากรใน Environment ต่างๆเข้าด้วยกัน เพื่อให้การใช้งาน GPU มีประสิทธิภาพสูงสุด และสอดคล้องกับเป้าหมายทางธุรกิจ ให้องค์กรสามารถเริ่มต้นกับส่วนการทำงานระดับ AI Workload ได้ง่ายขึ้นทั้งวงจร แต่สิ่งที่ยังขาดหายไปก็คือ NVIDIA Run:ai ต้องอาศัยอยู่บนแพลตฟอร์มของ Kubernetes ที่สามารถบริหารและจัดการได้ง่าย ซึ่งเป็นที่รู้กันว่าการบริหารจัดการ Kubernetes เองเป็นอะไรที่ซับซ้อนและยากในการจัดการแบบ Full Stack (Compleate Stack) ทั้ง Network, Security, Observability, Storage และ Resiliency นั่นคือความสำคัญของ VMware Cloud Foundation ที่จะเข้ามาจัดการความท้าทายส่วนนี้
ซึ่งเมื่อเร็วๆนี้ ทางวีเอ็มแวร์ได้ประกาศว่าองค์กรสามารถติดตั้งและใช้งาน NVIDIA Run:ai ร่วมกับ VMware Cloud Foundation (VCF) ได้แล้ว โดยการผสานการทำงานนี้จะช่วยให้องค์กรสามารถใช้ทรัพยากรได้อย่างสูงสุดและมีประสิทธิภาพขึ้นไปอีก ด้วย NVIDIA Run:ai จะช่วยลดความซับซ้อนในการติดตั้งและบริหาร Kubernetes และรองรับการใช้งานทั้งแบบ Containner และ VMs บนแพลตฟอร์ม VMware Cloud Foundation (VCF)
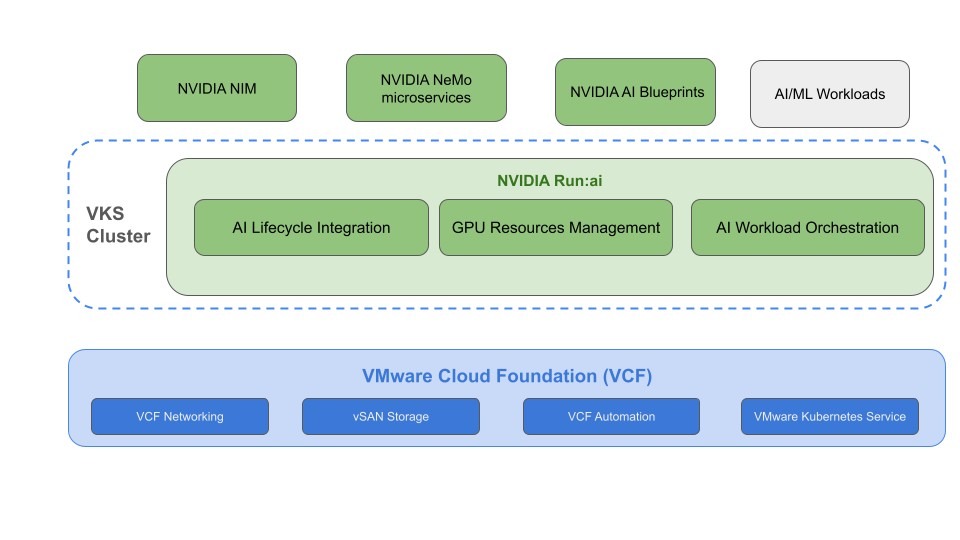
การทำงานของ NVIDIA และ VMware ทำได้ 2 ทางเลือก 2 ดังนี้
- ติดตั้ง NVIDIA Run:ai บน VCF instance ที่เปิดใช้ vSphere Kubernetes Service(VKS) ซึ่งเป็น Enterprise Ready และ Cloud Native Computing Foundation (CNCF) certified ready Kubernetes Cluster เหมาะสำหรับองค์กรที่ต้องการบริหารจัดการทรัพยากรณ์ แบบ Fully Automated ทั้งหมด ทำงานร่วมกับความสามารถ ของแพลตฟอร์ม VMware Cloud Foundation (VCF) ได้อย่างไร้รอยต่อ เช่น ประโยชน์จาก vSphere HA สำหรับงานประมวลผลที่ต้องกินเวลานานรอดจากเหตุฮาร์ดแวร์เสียหาย หรือแม้แต่ vMotion เพื่อให้การทำ maintenance ของ infrastructure เป็นไปได้ง่ายโดยไม่ต้องหยุดการทำงานของ AI workload เป็นต้น
- เชื่อมต่อ vSphere Kubernetes Service(VKS) เข้าไปยัง NVIDIA Run:ai ที่มีอยู่แล้ว กระบวนการนี้มีขั้นตอนน้อยกว่าวิธีการแรก แต่ยังช่วยให้องค์กรได้ประโยชน์ในการมองเห็นภาพการทำงานและควบคุมการทำงานได้บางส่วน โดย NVIDIA สามารถการจัดการ GPU และ Policy ได้กับ VCF ส่วนนี้
การใช้งาน NVIDIA Run:ai บน VMware VCF ยังมีอีกหลายเหตุผลที่ทำให้ทางเลือกนี้มีความน่าสนใจ เช่น
- ใช้เครื่องมือเดิมสำหรับจัดการ Workload ทั้งองค์กร – VMware Cloud Foundation เป็นแพลตฟอร์มที่รองรับการจัดการ Workload ได้ทั้ง Container และ VM ซึ่งเป็นที่คุ้นเคยกันในองค์กรอยู่แล้ว ดังนั้นผู้ใช้งานจึงไม่จำเป็นต้องเรียนรู้ใหม่ในการจัดการ Kubernetes คลัสเตอร์ที่เป็นพื้นฐานของ NVIDIA Run:ai ทั้งยังไม่ต้องเสียเวลาเรียนรู้เครื่องมือใหม่อีกด้วย พร้อมระบบอัตโนมัติสำหรับการจัดเตรียมคลัสเตอร์และ GPU Operator การอัปเกรด และการบริหารจัดการตลอดการใช้งานอีกด้วย
- Kubernetes รองรับโดย CNCF และดูแลยาวนาน – VMware vSphere Kubernetes Service (VKS) เป็น Kubernetes Runtime ที่ได้รับการรับรองโดย CNCF ซึ่งผู้ใช้งานสามารถใช้คำสั่งมาตรฐานในการจัดการ หรือการใช้ผ่านหน้า UI นอกจากนี้ยังสามารถขยายระยะเวลาการอัปเดตบ่อยครั้งของ Kubernetes โดย VMware รองรับการดูแล Kubernetes เวอร์ชันย่อยสูงสุดถึง 24 เดือน สำหรับแต่ละเวอร์ชันย่อยของ vSphere Kubernetes (VKr) ช่วยลดความกังวลในการอัปเกรดตาม Kubernetes ต้นทาง ทำให้สภาพแวดล้อมมีความเสถียร และช่วยให้ทีมสามารถโฟกัสกับการส่งมอบระบบ และ ช่วยให้ทีมไอทีได้มีเวลาในการวางแผนการอัปเดตตรวจสอบให้มั่นใจอีกด้วย
- ตอบโจทย์ Compliance และความเป็นส่วนตัว – ในหลายธุรกิจการใช้งานข้อมูลของ AI/ML เป็นเรื่องที่เสี่ยงต่อความมั่นคงปลอดภัยของข้อมูล ทำให้หลายองค์กรไม่สามารถริเริ่มโครงการ AI ได้ โดยแพลตฟอร์ม VMware Cloud Foundation ได้มอบประสบการณ์แบบคลาวด์แต่ช่วยรักษาความเป็นส่วนตัวของข้อมูลไว้ภายในองค์กร นอกจากนี้ยังสามารถแยกสภาพแวดล้อมของ Kubernetes Cluster สำหรับแต่ละการใช้งานได้ ที่อาจมีระดับการดูแลด้านความมั่นคงปลอดภัยแตกต่างกัน
- ลดงาน Container Networking – การใช้การ Container Networking ก็เป็นอีกหนึ่งความท้าทายเมื่อมี Kubernetes Cluster จำนวนมาก ซึ่งท่านจะต้องคอยจัดการการเชื่อมต่อ แต่ในกรณีของ VMware Cloud Foundationb ที่มาพร้อมกับ Container Network Interface(CNI) ซึ่งอ้างอิงจาก Cloud Native Computing Foundation (CNCF) โปรเจค sandbox ที่ชื่อว่า Antrea ซึ่งจะถูกใช้เป็น Container Network Interface (CNI) พื้นฐานเมื่อท่านเปิด vSphere Kubernetes Service (VKS) ทำให้จัดการเครือข่ายภายในคลัสเตอร์ สร้าง Network Policy ที่จัดการจากศูนย์กลาง ติดตามการทำงานจาก NSX ได้ หรืออาจเลือกใช้ Calico เป็น Container Network Interface (CNI) แทนก็สามารถทำได้เช่นกัน
- ยกระดับความปลอดภัยด้วย VMare vDefend – ผู้ใช้งาน VMware Cloud Foundation ใน AI คลัสเตอร์ที่มีหลายแอปพลิเคชันใช้งานร่วมกัน มักต้องการระดับความปลอดภัยและการควบคุมการเข้าถึงที่แตกต่างกัน ซึ่งการบังคับใช้อย่างสม่ำเสมอทำได้ยาก ซึ่งเรา สามารถเพิ่ม vDefend ที่เป็นความสามารถขั้นสูงจากการเปิด Antrea เพิ่มจัดการทราฟฟิคระดับ East-West สู่ Container โดยทำให้ผู้ใช้สามารถแบ่งแยกส่วน AI Workload, Data Pipeline และ Tenant namespace ได้อย่างปลอดภัย ลดโอกาสของการขยายวงการโจมตีเมื่อถูกเจาะ ทำให้ IT สามารถแยกและควบคุม AI workloads, data pipelines และแต่ละ tenant ได้ด้วยนโยบายแบบ software-defined และ zero-trust
- ระบบ Storage ที่ยืดหยุ่นและบริหารจัดการแบบ Policy โดย vSAN – งานด้าน AI มีความต้องการด้าน Storage ที่หลากหลาย เช่น พื้นที่ความเร็วสูง (high-IOPS) สำหรับงานเทรนนิ่ง หรือ Object Storage ที่มีความทนทานสำหรับเก็บชุดข้อมูล ด้วยความสามารถของ vSAN องค์กรสามารถบริหารจัดการ Storage ตามความเหมาะสมกับ Workload ผ่าน storage policy ทำให้ไม่ต้องแยกสร้างระบบ Storage หลายชุดหรือเกิด infrastructure silo แบบที่มักพบในสภาพแวดล้อมแบบ storage ทั่วไป
- เสริมความพร้อมใช้งานและระบบอัตโนมัติขั้นสูงด้วย VMware vSphere – เมื่อความแข็งแกร่งของโครงสร้างพื้นฐานเป็นเรื่องที่สำคัญ เพราะหากเซิร์ฟเวอร์แบบ bare-metal ที่รันงานเทรนนิ่งสำคัญเกิดความล้มเหลวระดับฮาร์ดแวร์ขึ้นย่อมเกิดความสูญเสียเป็นอย่างมาก แต่หากเราทำงานบน VMware Cloud Foundation ที่ขับเคลื่อนด้วย vSphere HA ระบบจะสามารถรีสตาร์ต workload เหล่านั้นขึ้นมาบนโฮสต์อื่นได้โดยอัตโนมัติ ช่วยลดผลกระทบและเพิ่มความต่อเนื่องในการทำงาน และนอกจากนี้ระบบ ยังมีความสามารถที่ช่วยในการย้าย Workload แบบ non-disruptive ด้วย vMotion หรือการทำงานของ vSphere HA หรือแม้กระทั่งการสำรองข้อมูลด้วย Velero ที่ตอบโจทย์งาน Backup & DR ให้ vSphere Kubernetes Cluster และ vSphere Pods นอกจากนี้ Dynamic Resource Scheduling (DRS) จะปรับสมดุลการใช้ทรัพยากรโดยอัตโนมัติเพื่อป้องกันการเกิดคอขวดหรือจุดที่โหลดสูงเกินไป (hotspots) ซึ่งการทำงานอัตโนมัติลักษณะนี้จะไม่สามารถทำงานได้ในสภาพแวดล้อมแบบ bare-metal
- ความสามารถด้าน Observability – การติดตามการทำงานบน Kubernetes ถือเป็นอีกหนึ่งหัวข้อใหญ่ หากท่านเลือกใช้ Kubernetes Stack แบบปกติที่ไม่ได้มีเครื่องมือเหล่านี้มาให้ ผู้ใช้งานต้องจัดหาเครื่องมือเพิ่ม เช่น Grafana, Prometheus และอื่นๆ แต่ก็ยังไม่ครอบคลุมเครื่องฮาร์ดแวร์ GPU และเครือข่าย เทียบกับ VCF Operations Fleet Management ใน VCF 9.0 ที่มอบความสามารถเหล่านี้มาให้แล้ว แบบ Single Plane of Glass ตั้งแต่ในระดับ Physical layer, ไปจนถึง Hypervisor และขึ้นไปถึง Kubernetes Cluster (VKS) นอกจากนี้ ยังมี VCF Operations GPU Dashboard เฉพาะ ที่ช่วยแสดงข้อมูลสำคัญเกี่ยวกับการใช้งาน GPU และ vGPU ของแอปพลิเคชันต่าง ๆ ทำให้เข้าใจพฤติกรรมการใช้ทรัพยากรของ AI workload ได้ชัดเจนยิ่งขึ้น และด้วยข้อมูลเชิงลึกที่ออกแบบมาสำหรับงาน AI โดยเฉพาะ ช่วยให้สามารถระบุและแก้ไขคอขวดได้รวดเร็ว
บทสรุป
ในบทความนี้เราได้พาทุกท่านไปรู้จักกับ NVIDIA Run:ai ที่ช่วยแก้ปัญหาให้กับผู้ปฏิบัติการด้าน AI ที่เกิดขึ้นจริงในการทำงาน ทำให้องค์กรปลดล็อกการทำงานของ GPU บนสภาพแวดล้อมที่หลากหลายโดยไม่ต้องแก้ไขโค้ด ทำให้ใช้ทรัพยากรที่แสนแพงนี้ได้คุ้มค่าและเพียงพอต่อจุดมุ่งหมายทางธุรกิจ อย่างไรก็ดีพื้นฐาน NVIDIA Run:ai ยังต้องอาศัย Kubernetes ที่เป็นเรื่องยุ่งยากในองค์กร นั่นจึงทำให้ VMware Cloud Foundation กลายมาเป็นคู่ผสมที่ลงตัว ด้วยฟีเจอร์ระดับองค์กรมากมายสำหรับ Kubernetes พร้อมตอบโจทย์เงื่อนไขด้านธุรกิจ และ Compliance ในเครื่องมือที่องค์กรคุ้นเคยมาอย่างยาวนาน มอบประสบการณ์การใช้งานแบบคลาวด์
สำหรับผู้ที่สนใจโซลูชันของ VMware หรือกำลังมองหาแนวทางการสร้าง Private Cloud สามารถติดต่อทีมงาน VST ECS (Thailand) ได้ที่ vmwareconnect@vstecs.co.th
แหล่งที่มาของข้อมูล: techtalkthai.com
